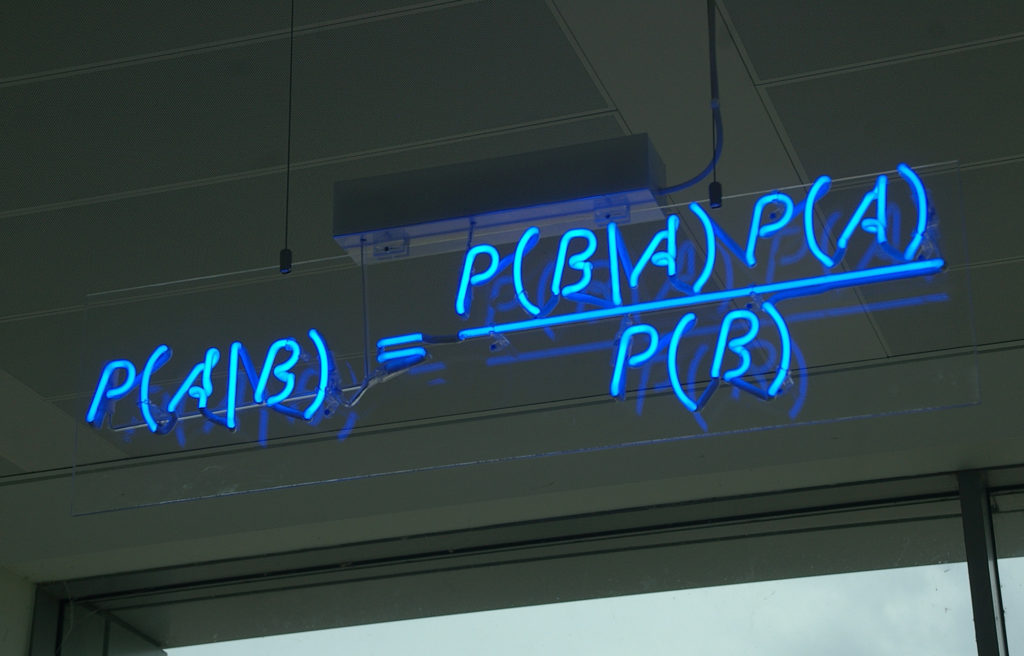Every once in a while, I join events aimed at Early Career Researchers to talk about possible career paths, some personal experience in job hopping and to hopefully give some useful advice for ECRs when they’re on cross-roads in their professional life path. I like these events and find them to be very helpful for bouncing thoughts and raising awareness for aspects of career decisions that are not always on top of mind. For sure, there were things that I would have hoped to realize earlier in life. If you’re in need of somebody to exchange thoughts on such matters, feel free to contact me on LinkedIn or by email.
It’s important to have a bunch of people at such events, who all bring their own perspectives, experiences and personalities. A good choice for your own career depends on countless factors, and there really is no golden recipe for a successful, happy progression of your professional life. That said, there are some general things you might want to consider, and I wish events like the ones I sometimes attend would have been present 15 years ago, to teach my past me.
The event I attended yesterday was extra special. The yearly Dutch Astronomers Conference (also known under its Dutch name of Nederlandse Astronomen Conferentie, NAC) had an ECR event. For me, it was 14 years ago that I attended my last NAC. I had great memories of the meetings, packed with interesting science, but also a lot of fun social events in a great community. It was incredibly fun to meet old friends again. Obviously, I knew basically nobody of the younger generation, but I was surprised to see how many people I did still recognize. It felt like a reunion, or even like coming home after a long absence.
It was extra amazing that my master’s thesis advisor, and the astronomer who has been my great example ever since studying in Utrecht, was at the meeting, and attended my talk, too. As a scientist, teacher, mentor and astronomy popularizer, I do not know of a better example. Henny, thank you for catching up, and for being there yesterday and those numerous times before. It means the world to me. And indeed: if anybody would have inspired me to stay in astronomy, it would have been you.
The numerous valuable encounters made yesterday great. I hope that I added some value to the younger audience, who are facing some tough yet important decision on how to shape their future lives. In case it might useful to anybody, here are my slides for the event:
Vanna, thanks for organizing these valuable events and keep up the good work with the NOVA-SKIES mentoring program! Stefania, thanks for the laughs and the ride home! Congrats and thanks for the fun, Steven. Lex: my memories (of 23 years ago!!) are fantastic too. They shaped my early astronomy life and they will last a lifetime, I’m sure. Scott, we need to keep the picture tradition alive, so in decades we can study some evolutionary patterns! Ilse, three events in a timeframe of just a couple of hours is impressive; good luck in your new role! And also to all the others I caught up with yesterday: thanks, I had a blast.
I very recently quit a teaching program that I have been part of for more than four years, to which I had a personal connection after all those years. Besides it being lucrative, it was also a program that was for a good part shaped by me and colleagues and which was fun and fulfilling to teach. Why quit, you might ask.
The program, consisting of modules for data scientists, analytics translators and managers/executives, was a collaboration between a consulting company, Ortec, and the Amsterdam Business School, a department of the University of Amsterdam that organizes a lot of executive education. The data scientist program was ruthlessly killed about a year ago, because of fierce competition from online platforms. Face-to-face education is more effective and in my opinion worthwhile, but if you can’t offer the right program for the right price, then it isn’t weird to decide not to. That so many people think you can learn such skills through watching a few videos and typing in two lines of code in a automatically checking code interpreter continues to amaze me and I bet we will see the devastating effects of this, now still junior, generation of Youtube data scientists in due time. But I digress.
The module for analytics translators is still alive and just these past few months I have still been teaching it. Fulfilling as always, I spent two half days in lecture rooms in hotels with a group of enthusiastic participants. The program this time was already rather different from what it had been before, and with the feedback of the current cohort, leadership decided to do another round of modifications.
Do not misunderstand me: continuously updating your educational offerings is what a good teacher does. Incorporating feedback from participants (or students) is crucial, as only they can properly judge whether your efforts help them reach their learning goals. One quote of the program director in the process made me scratch my head though:
I am just trying to design a program that I can sell.
Sure, selling your program is important, as otherwise there is no program. I get that. And for consulting companies (this program director is not with the consulting party in the collaboration) this may be the most or even only viable way of running business. I think, though, that people come to trusted educational institutions like universities for a different reason. A university does not design a curriculum for sales. It sets learning goals (which may well be (job-) market informed!) and then designs an educational pathway to best reach those goals. What people need to learn is determined by where they want to end up, not by what is a sexy set of courses that happens to be easily marketed.
Teachers are teaching what they teach for two reasons. Firstly, they want to convey knowledge and skills that they have to students who want to learn. They think about the right educational means to help the students gain the knowledge and master the skills. Secondly, they are specialists in the field in which they teach, which means that they understand like no other what is necessary to learn, before one can become a specialist in that field, too. Few astronomers truly enjoy the first-year linear algebra they need to master and rarely do psychologist enjoy their statistics classes in undergrad, but these happen to be crucial ingredients to grow into the field that you want to be part of.
Besides the communication between the various people in this program detoriating to levels that I didn’t want to accept anymore, the fact that the curriculum went from specialist-informed to marketing and sales opportunity informed was the straw that broke the camel’s back. I want to be a proud teacher. Proud teachers design a program that is the best they can do to help students reach meaningful goals. You are very welcome to set learning goals based on all kinds of arguments, including sales, but once the learning goals are set, you should trust the professional’s teaching experience to manufacture a great, fun, and helpful course or program. It will be better for everyone’s motivation.
PS. More on my new academic role soon, presumably!
We’re at the start of 2023. It has almost become a habit for me to switch jobs about yearly, over the last few years. I have never intended it that way, but apparently I needed a few de-tours to find out where I wanted to go. I have not made it a secret that I regret quitting my astro career and I also have alluded to aspiring an academic career. My current job at the University of Amsterdam is adjacent to academia, and that was the whole reason I took it in the first place.
I have done fun projects, learned a lot about the ‘behind the scenes’ at universities and was a willingly active member in the interdisciplinary Data Science Center of the University of Amsterdam (UvA). Some things could have been better (“creating” demand for our work wasn’t overly successful, and support from IT for what we needed was consistently cut back to near zero budget), but I do not necessarily need to change jobs. With my leave, though, I have advised against replacing me by another Marcel. I think the money can be spent better, before another me would jump onto the Advanced Analytics bandwagon again at the UvA central administration. Thanks to all my colleagues at the UvA for an interesting and fun year and a half!
In the post that announced my current job, I described the road towards it, which included a second place in a race for an assistant professorship at a university medical center, shared with a computer science department. In a rather bizarre turn of events (details available off the record), I have eventually accepted an offer that is very comparable, and arguably even better than the position I was originally applying for. That means…
I’m proud to announce that as of Feb 1st, I’ll be an academic again!
I’m very excited to be giving a lot of serious education again, and to be doing research in a highly relevant field of science. I have very little network or track record in this field, so I expect to learn a whole lot! Keep an eye on this blog, I might be using it a bit more frequently again (no guarantees, though…). Here’s to a challenging, but fun 2023!
I have indicated already earlier on this blog that I miss academia, and that I wouldn’t mind moving back into an academic job. I have made some attempts recently and want to reflect on the process here. Spoiler alert: I’ll start a job at the University of Amsterdam very soon!
In my journey back into academic life I have also applied less successfully twice, and for reflection on that, it is probably useful to understand my boundary conditions:
I left my academic career in astrophysics now roughly 8 years ago and have not done any pure science since (at least not visibly).
I have few, too few papers from three years of postdoc. I left my postdoc position with no intention to go back, and therefore have just dropped all three first-author papers that were in the making on the spot. They were never and will never be published.
I am strongly geographically bound. I can commute, but I can not move. Hence, I am bound to local options.
I have spent these last 8 years on data science and gained a fair amount of experience in that field. All that experience is in applied work. I have not done any fundamental research on data science methodology, As an aside, I have of course learned a lot about software development and team work in companies of different sizes. I have seen the process of going from a Proof-of-Concept study to building actual products in a scalable, maintainable production environment (often in the cloud) up close, very close. Much of that experience could be very useful for academia. If I (and/or my collaborators) back then had worked with standards even remotely resembling what is common in industry, science would progress faster, it would suffer much less from reproducibility issues and it would be much easier to build and use science products for a large community of collaborators.
But I digress…. The first application for an assistant professorship connected closely to some of the work I have done in my first data science job. I spent 5,5 years at a healthcare insurance provider, where some projects were about the healthcare side of things, as opposed to the insurance business. The position was shared between a university hospital and the computer science institute. I applied and got shortlisted, to my surprise. After the first interview, I was still in the race, with only one other candidate left. I was asked to prepare a proposal for research on “Data Science in Population Health” and discussed the proposal with a panel. It needed to be interesting for both the hospital as well as for the computer scientists, so that was an interesting combination of people to please. It was a lot of fun to do, actually, and I was proud of what I presented. The committee said they were impressed and the choice was difficult, but the other candidate was chosen. The main reason was supposedly my lack of a recent scientific track record.
What to think of that? The lack of track record is very apparent. It is also, I think, understandable. I have a full time job next to my private/family life, so there is very little time to build a scientific track record. I have gained very relevant experience in industry, which in fact could help academic research groups as well, but you can’t expect people to build experience in a non-academic job and build a scientific track record on the side, in my humble opinion. I was offered to compete for a prestigious postdoc-like fellowship at the hospital for which I could fine-tune my proposal. I respectfully declined, as that was guaranteed to be short-term, after which I would be without a position again. In fact, I was proud to end with the silver medal here, but also slightly frustrated about the main reason for not getting gold. If this is a general pattern, things would look a little hopeless.
As part of my job, and as a freelancer, I have spent a lot of time and effort on educational projects. I developed training material and gave trainings, workshops and masterclasses on a large variety of data science-related topics, to a large variety of audiences. Some of those were soft skill trainings, some were hard skill. Most were of the executive education type, but some were more ‘academic’ as well. When at the astronomical institute at biking distance a job opening with the title “Teaching assistant professor” appeared I was more than interested. It seemed to be aimed at Early Career Scientists, with a very heavy focus on education and education management. Contrary to far most of the job openings I have seen at astronomical institutes, I did not have to write a research statement, nor did they ask for any scientific accomplishment (at least not literally in the ad, perhaps this was assumed to go without saying). They asked for a teaching portfolio, which I could fill with an amount of teaching that must have been at least on par with successful candidates (I would guess the equivalent of 6 ECTS per year, for 3 years on end, and some smaller, but in topic more relevant stuff before that) and with excellent evaluations all across. Whatever was left of the two pages was open for a vision on teaching, which I gladly filled up as well. Another ingredient that would increase my chances was that this role was for Dutch speaking applicants and that knowledge of the Dutch educational system was considered a plus. Score and score. That should have significantly narrowed the pool of competitors. In my letter, I highlighted some of the other relevant experience I gained, that I would gladly bring into the institute’s research groups.
Right about at the promised date (I was plenty impressed!), the email from the selection committee came in! “I am sorry that we have to inform you that your application was not shortlisted.” Without any explanation given, I am left to guess what was the main issue with my application here. I wouldn’t have been overly surprised if I wasn’t offered the job, but I had good hopes of at least a shortlist, giving me the opportunity to explain in person why I was so motivated, and in my view qualified. So, were they in fact looking for a currently practicing astronomer? Was research more important than the job ad made it seem? Is my teaching experience too far from relevant, or actually not (good) enough? Dare I even question whether even this job ad was actually aiming for top-tier researchers rather than for people with just a heart (and perhaps even talent) for teaching? It’s hard to guess what the main reason was, and I shouldn’t try. One thing I am reluctantly concluding from this application is that a job in professional astronomy is hard to get for somebody who has long left the field. I think this vacancy asked for experience and skills that match my profile very well, so not even being shortlisted says a lot to me. Perhaps that’s not grounded, but that’s how it goes with sentiment, I guess. Perhaps a dedicated data science job in astronomy is still feasible, who knows.
In September, I’ll join the University of Amsterdam.
But alas, as said, I have also applied successfully. Yay! The University of Amsterdam (UvA) had an opening for a lead data scientist in the department of policy and strategy. Working for, rather than in higher education was something that previously didn’t really occur to me, but this really sounds like an opportunity to do what I like to do and do well, in the field where my heart is. The UvA is putting emphasis on data literacy in education as well as (inter-disciplinary) research. Big part of the job will be to build and maintain a network inside and outside of the university with data science communities. The Amsterdam Data Science Center fosters research that uses data science methods and meets around the corner. I will strive to take a central, or at least very visible role in that Center and be very close to academic interdisciplinary research! I’m excited! In due time, I’ll report on my experience.
I was already convinced years ago, by videos and a series of blog posts by Jake VanderPlas (links below), that if you do inference, you do it the bayesian way. What am I talking about? Here is a simple example: we have a data set with x and y values and are interested in their linear relationship: y = a x + b. The numbers a and b will tell us something we’re interested in, so we want to learn their values from our data set. This is called inference. This linear relationship is a model, often a simplification of reality.
The way to do this you learn in (most) school(s) is to make a Maximum Likelihood estimate, for example through Ordinary Least Squares. That is a frequentist method, which means that probabilities are interpreted as the limit of the relative frequencies for very many trials. Confidence intervals are the intervals that describe where the data would lie after many repetitions of the experiment, given your model.
In practice, your data is what it is, and you’re unlikely to repeat your experiment many times. What you are after is an interpretation of probability that describes the belief you have in your model and its parameters. That is exactly what Bayesian statistics gives you: the probability of your model, given your data.
For basically all situations in science and data science, the Bayesian interpretation of probability is what suits your needs.
What, in practice, is the difference between the two? All of this is based on Bayes’ theorem, which is a pretty basic theorem following from conditional probability. Without all the interpretation business, it is a very basic result, that no one doubts and about which there is no discussion. Here it is:
Bayes’ theorem reads as: The probability of A, given B (the “|B” means “given that B is true”) equals the probability of B, given A times the probability of A, divided by the probability of B. Multiplying both sides with P(B) results in the probability of A and B on both sides of the equation.
Now replace A by “my model (parameters)” and B by “the data” and the difference between inference in the frequentist vs Bayesian way shines through. The Maximum Likelihood estimates P(data | model), while the bayesian posterior (the left side of the equation) estimates P (model | data), which arguably is what you should be after.
As is obvious, the term that makes the difference is P(A) / P(B), which is where the magic happens. The probability of the model is hat is called the prior: stuff we knew about our model (parameters) before our data came in. In a sense, we knew something about the model parameters (even if we knew very very little) and update that knowledge with our data, using the likelihood P(B|A). The normalizing factor P(data) is a constant for your data set and for now we will just say that it normalizes the likelihood and the prior to result in a proper probability density function for the posterior.
The posterior describes the belief in our model, after updating prior knowledge with new data.
The likelihood is often a fairly tractable analytical function and finding it’s maximum can either be done analytically or numerically. The posterior, being a combination of the likelihood and the prior distribution functions can quickly become a very complicated function that you don’t even know the functional form of. Therefore, we need to rely on numerical sampling methods to fully specify the posterior probability density (i.e. to get a description of how well we can constrain our model parameters with our data): We sample from the priors, calculate the likelihood for those model parameters and as such estimate the posterior for that set of model parameters. Then we pick a new point in the priors for our model parameters, calculate the likelihood and then the posterior again and see if that gets us in the right direction (higher posterior probability). We might discard the new choice as well. We keep on sampling, in what is called Markov Chain Monte Carlo process in order to fully sample the posterior probability density function.
On my github, there is a notebook showing how to do a simple linear regression the Bayesian way, using PyMC3. I also compare it to the frequentist methods with stasmodels and scikit-learn. Even in this simple example, a nice advantage of getting the full posterior probability density shines: there is an anti-correlation between the values for slope and intercept that makes perfect sense, but only shows up when you actually have the joint posterior probability density function:
A linear regression performed on the data shown on the left and the joint posterior probability shown on the right. From a Maximum Likelihood or the marginal likelihoods of the fit results, this anti-correlation between slope and intercept would not have been so clear. In the mean time, the analysis also gave us the standard deviation around the fit, see the notebook for details.
Admittedly, there is extra work to do, for a simple example like this. Things get better, though, for examples that are not easy to calculate. With the exact same machinery, we can attack virtually any inference problem! Let’s extend the example slightly, like in my second bayesian fit notebook: An ever so slightly more tricky example, even with plain vanilla PyMC3. With the tiniest hack it works like a charm, even though the likelihood we use isn’t even incorporated in PyMC3 (which makes it quite advanced already, actually), we can very easily construct it. Once you get through the overhead that seems killing for simple examples, generalizing to much harder problems becomes almost trivial!
I hope you’re convinced, too. I hope you found the notebooks instructive and helpful. If you are giving it a try and get stuck: reach out! Good luck and enjoy!
A great set of references in “literature”, at least that I like are:
Astronomy has always been a “big data science”. Astronomy is an observational science: we just have to wait, watch, see and interpret what happens somewhere on the sky. We can’t control it, we can’t plan it, we can just observe in any kind of radiation imaginable and hope that we understand enough of the physics that governs the celestial objects to make sense of it. In recent years, more and more tools that are so very common in the world of data science have also penetrated the field of astrophysics. Where observational astronomy has largely been a hypothesis driven field, data driven “serendipitous” discoveries have become more commonplace in the last decade, and in fact entire surveys and instruments are now designed to be mostly effective through statistics, rather than through technology (even though it is still stat of the art!).
In order to illustrate how astronomy is leading the revolutions in data streams, this infographic was used by the organizers of a hackathon I went to nearing the end of April:
The Square Kilometer Array will be a gigantic radio telescope that is going to result in a humongous 160 TB/s rate of data coming out of antennas. This needs to be managed and analysed on the fly somehow. At ASTRON a hackathon was organized to bring together a few dozen people from academia and industry to work on projects that can prepare astronomers for the immense data rates they will face in just a few years.
As usual, and for the better, smaller working groups split up and started working on different projects. Very different projects, in fact. Here, I will focus on the one I have worked on, but by searching for the right hash tag on twitter, I’m sure you can find info on many more of them!
We jumped on two large public data sets on galaxies and AGN (Active Galactic Nuclei: galaxies with a supermassive black hole in the center that is actively growing). One of them was a very large data set with millions of galaxies, but not very many properties of every galaxy (from SDSS), the other, out of which the coolest result (in my own, not very humble opinion) was distilled was from the ZFOURGE survey. In that data set, there are “only” just under 400k galaxies, but there were very many properties known, such as brightnesses through 39 filters, derived properties such as the total mass in stars in them, the rate at which stars were formed, as well as an indicator whether or not the galaxies have an active nucleus, as determined from their properties in X-rays, radio, or infrared.
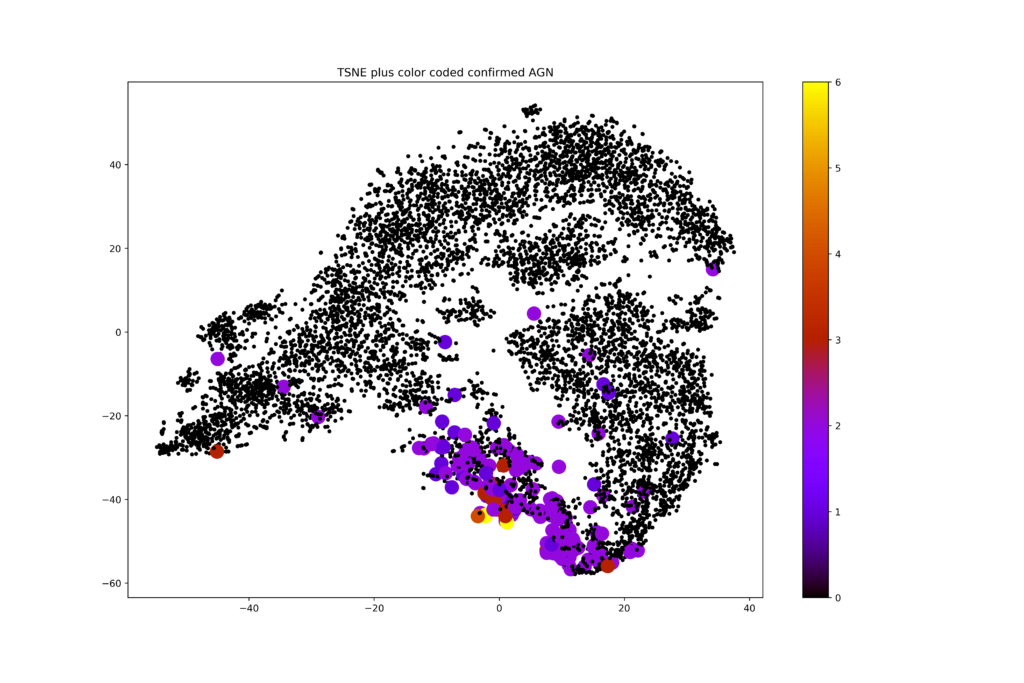
I decided to try something simple and take the full photometric set of columns, so the brightness of the objects in many many wavelengths as well as a measure of their distance to us into account and do some unsupervised machine learning on that data set. The data set had 45 dimensions, so an obvious first choice was to do some dimensionality reduction on it. I played with PCA and my favorite bit of magic: t-SNE. A dimensionality reduction algorithm like that is supposed to reveal if any substructure in the data is present. In short, it tends to conserve local structure and screw up global structure just enough to give a rather clear representation of any clumping in the original high dimensional data set, in two dimensions (or more, if you want, but two is easiest to visualize). I made this plot without putting in any knowledge about which galaxies are AGN, but colored the AGNs and made them a bit bigger, just to see where they would end up:
To me, it was absolutely astonishing to see how that simple first try came up with something that seems too good to be true. The AGN cluster within clumps that were identified without any knowledge of the galaxies having an active nucleus or not. Many galaxies in there are not classified as AGN. Is that because they were simply not observed at the right wavelengths? Or are they observed but would their flux be just below detectable levels? Are the few AGN far away from the rest possible mis-classifications? Enough questions to follow up!
On the fly, we needed to solve some pretty nasty problems in order to get to this point, and that’s exactly what makes these projects so much fun to do. In the data set, there were a lot of null values, no observed flux in some filters. This could either mean that the observatory that was supposed to measure that flux didn’t point in the direction of the objects (yet), or that there was no detected flux above the noise. Working with cells that have no number at all or only upper limits on the brightness in some of the features that were fed to the machine learning algorithm is something most ML models are not very good at. We made some simple approximations and informed guesses about what numbers to impute into the data set. Did that have any influence on the results? Likely! Hard to test though… For me, this has sprung a new investigation on how to deal with ML on data with upper or lower limits on some of the features. I might report on that some time in the future!
The hackathon was a huge success. It is a lot of fun to gather with people with a lot of different backgrounds to just sit together for two days and in fact get to useful results, and interesting questions for follow-up. Many of the projects had either some semi-finished product, or leads into interesting further investigation that wouldn’t fit in two days. All the data is available online and all code is uploaded to github. Open science for the win!
Most who know me will probably know that I’m a major fan of Python in particular and open source software in general. Still, in my day job I use SAS quite a lot. Because I will be at the SAS Global Forum in Denver next week, I thought it would be a good time to write about the place of SAS in my work.
First of all, I can obviously not pay for the massive license fees of software like SAS, which also is my biggest objection to using it. So when I do anything on a freelance basis, it will be purely Python, in almost all assignments. In my day job I arrived, now 4,5 years ago, in a team that even was called the “SAS team”. Their main, and in fact for a long time only, tooling was SAS Base. After fighting for a good two years we do now have a decent Anaconda installation with a Jupyter Hub which makes for much faster data exploration, easier analytics and easier and much prettier visualization (no, SAS Visual Analytics is *not* a visualization tool, it’s a dashboarding tool, enormous difference).
Alright, so I can use Python and R and I still use SAS? Indeed I do. I think every tool is good for something. Part of our team is mainly occupied with ETL (extract, transform, load) work, building a good, stable, clean and well structured data warehouse that others (like me) can use at ease. For such work, SAS has some great tools. Moving data from a data base that is designed to make a particular application work smoothly into a data warehouse, that keeps track of the history of that data base as well is not a trivial task and keeping track of all relevant input data base changes is quite some work. This is done with SAS (by others) and results in a data warehouse stored in SAS data sets that I consequently use for data analysis, machine learning, you name it.
From a data warehouse in SAS tables, I find it easiest to do my data collection, merging, aggregation and all that prerequisite work one always needs for analytics in SAS as well. Most of my projects start with data wrangling in SAS, and when I get to a small number of tables that are ready for analysis, analytics or visualization, I move over to Python (where the fun starts).
Yes, I do have my strong opinions about many SAS tools, about SAS as a company, about how they work and about how the world (e.g. auditors, authorities) look at SAS versus how they look at software from the open source realms. Still, I use a tool that is good at what I need from it, if I have access to it. More and better interfacing between Python, R and SAS is well underway and I hope the integration between the two will only become smoother. Hoping that SAS would vanish from my world is just an utterly unrealistic view of the world.
Two weeks ago I had nothing to do on a Saturday afternoon. Geeky as I am, I thought “let’s upgrade Xubuntu” on my laptop. I was still on the 16.04 Long Term Support version and it is 2018 by now, after all. A month or so later the new LTS version, 18.04, would appear, but why wait? That afternoon I had nothing better to do; when the new version comes out, I probably will be occupied. As usual, I googled around about a version upgrade from 16.04 to 17.10 and was, by every single site I encountered on the topic, strongly advised not to try this. But alas, I’m as stubborn as data scientists get and went ahead anyway.
Ouch. There seemed to be no problem at all. The upgrade was fine, except for some small weird looking error from LibreOffice, which I hardly ever use anyway. Everything worked as it worked before, even with the same looks (then why would you upgrade, right?). I played a game of Go for a bit and then went and let all other software do their updates as well. The usual reboot went blazing fast. I was prompted for my password and then the shit hit the fan: black screen. Nothing. Light from under the keyboard, but that was the only sign of life.
That is when you all of a sudden need a second computer. In all my confidence I had not created a bootable USB stick before the upgrade, and I didn’t have an older one with me either. With a terribly slow and annoying Windows laptop I managed to create one and booted the laptop from that. All fine. Good, so let’s replace the new and corrupted OS with something from this stick. Apparently, when I previously had installed my laptop, there seemed to be no need for a mount point for /efi, and now there was. Annoyingly, this needed to be at the start of the partition table, screwing up pre-existing partitions on that disk. At that point I decided: alright, format the disk, decently partition the disk and a fresh install would make my dear laptop all young and fresh again. There are two SSDs in the machine, and there was a back up of my home on the second disk.
The new install works like a charm, and restoring a back up also calls for some more cleaning up. It all looks tidy again.
I know, not everybody will be a fan of the old-school conky stuff on the desktop, but it just tickles my inner nerd a bit (and I actually do use it to monitor the performance when something heavy is running, I sure like it better than a top screen!). Took a decent part of a day, altogether, so next time I might take the advise of fellow geeks a bit more seriously. On the other hand, after mounting the second disk and finding the backups intact, the short moment of relief is worth it.
(This is a blog published on the website of my employer, thought it would make a fair placeholder, sorry about the Dutch).
De zorg is al duur zat. Elke extra euro die moet worden uitgegeven omdat een zorgverlener de regels buigt moet achterhaald, of liever nog voorkomen worden. Probleem is dat “die euro” dan wel gevonden moet worden en dat is geen sinecure. Dit komt door enerzijds het enorme volume aan declaraties dat een zorgverzekeraar krijgt van alle zorgverleners bij elkaar en anderzijds het feit dat fraudeurs slimme dingen bedenken om vooral niet op te vallen. Hoe sporen we bij DSW fraudeurs op?
Op zoek naar outliers
Naast de meer traditionele manieren om fraude op te sporen gebruiken we bij DSW ook analysetechnieken om in de grote bergen data die we hebben patronen te ontdekken die zouden kunnen wijzen op frauduleus of ander onwenselijk gedrag. De tandarts die in een jaar 20 vullingen legt bij een familielid of de psychiater die 40 uur per dag zegt te werken is natuurlijk gauw gevonden, maar de meeste boeven pakken het toch slimmer aan. Precies daarom moeten wij nog slimmer zijn!
Voor het detecteren van rotte appels in een fruitmand vol zorgverleners gaan we er over het algemeen van uit dat de grote meerderheid zich niet misdraagt. Dit betekent dat we kunnen zoeken naar zogenaamde “outliers”, personen of instanties die zich net even anders lijken te gedragen dan de norm. Een complicerende factor is dat wij als zorgverzekeraar altijd maar een deel van het gedrag van een zorgverlener kunnen controleren, namelijk alleen de zorg die gedeclareerd wordt voor die patiënten die toevallig bij ons verzekerd zijn. Bij sommige instanties is dat misschien wel 60% van de populatie of meer, maar bij de meesten toch duidelijk minder, en we weten niet eens hoeveel precies. We hebben dus eerst wat werk te verzetten om analyses te doen op grootheden die niet zo gevoelig zijn voor het marktaandeel van DSW, zoals bijvoorbeeld kosten per verzekerde.
De score opbouwen
Alleen controleren op een getal als de gemiddelde kosten per verzekerde dekt de lading ook niet. Als een kwaadwillende zorgverlener dan kleine bedragen declareert voor een hoop mensen, dan gaat hij zelfs lager eindigen in kosten per verzekerde (terwijl hij in het aantal mensen waarvoor iets declareert juist weer zou opvallen). We kijken daarom naar heel veel van dit soort graadmeters tegelijk. Zo bouwen we een “score” op die aangeeft op hoeveel van dit soort anomaliedetecties (en andere controles) een zorgverlener opvalt, en hoe sterk hij opvalt.
Naast het detecteren van grootheden waarop een zorgverlener opvalt door ander gedrag dan zijn/haar concurrenten, kunnen we ook kijken naar signalen van verzekerden (“ik heb die behandeling helemaal niet gehad”), naar simpele regels als “geamputeerde ledematen kun je niet meer breken” of zelfs naar (zakelijke) verbanden tussen verschillende zorgverleners waardoor lucratieve doch frauduleuze werkwijzen kunnen worden overgebracht van de doorgewinterde oplichter naar de crimineel in spe.
Verder onderzoek
Alle ingrediënten van een totaalscore zijn hard te maken met statistiek, wet- en regelgeving of andere afspraken. Door het tweaken van de opbouw van zo’n totaalscore maken we een lijst waarvan we toch met enige zekerheid wel kunnen zeggen dat er iets loos is. Wanneer dergelijke signalen zijn gegenereerd dan pakken andere afdelingen dit doorgaans op voor verder onderzoek. Hiervoor levert ons datateam uiteraard nog wel data en analyses aan, maar het initiatief voor het uiteindelijk aanpakken ligt dan in de handen van de afdelingen die dichter bij de dagelijkse gang van zaken van een zorgverlener staan.